SWOT and the Global Measurement of Rivers from Space
For most of human history, rivers have been measured locally. Water levels were monitored using gauges installed at specific locations, flow rates were estimated from field observations, and large sections of many river systems remained poorly observed or entirely unmeasured. Even today, vast portions of the world lack continuous hydrological monitoring infrastructure. This limitation has affected flood prediction, water resource management, climate modeling, and ecosystem studies for decades.
The Surface Water and Ocean Topography mission, commonly known as SWOT, is changing that. Developed jointly by NASA Jet Propulsion Laboratory and Centre National d'Études Spatiales, with contributions from the Canadian Space Agency and the United Kingdom Space Agency, the mission provides the first capability to continuously measure rivers and surface water systems globally from space at high spatial resolution.
The scientific importance of this capability is substantial. Rivers are dynamic systems that transport water, sediment, nutrients, and energy across continents. They connect mountain snowpacks, wetlands, forests, agricultural regions, cities, and coastal systems into a single hydrological network. Variations in river flow influence drinking water supplies, food production, hydroelectric generation, biodiversity, and flood risk. Yet despite their importance, comprehensive global measurements have remained incomplete because conventional monitoring depends heavily on ground-based instruments.
SWOT addresses this limitation through radar interferometry, a technique capable of mapping water surface elevations across wide swaths of Earth’s surface. Unlike traditional satellite altimeters, which measure elevation directly beneath the spacecraft along a narrow ground track, SWOT measures two-dimensional surface topography over broad areas. This allows the mission to observe rivers, lakes, reservoirs, wetlands, and coastal waters with much greater spatial coverage.
At the center of the spacecraft is the Ka-band Radar Interferometer, or KaRIn. The instrument operates by transmitting microwave radar pulses toward Earth and receiving the reflected signals using two antennas mounted at opposite ends of a long deployable boom. Because the antennas observe the same surface from slightly different positions, the returned signals contain phase differences related to surface elevation. By combining these measurements interferometrically, scientists can reconstruct detailed topographic maps of water surfaces.
The engineering required to achieve this precision is considerable. Surface elevation changes in rivers are often small, and the instrument must distinguish variations on the order of centimeters from orbit. This requires extremely accurate knowledge of the spacecraft’s position, orientation, and antenna separation. The deployable boom structure must remain mechanically stable despite thermal expansion and orbital stresses. Timing systems and signal processing algorithms must maintain phase coherence between the two radar channels.
SWOT operates in low Earth orbit, repeatedly surveying nearly all of the planet’s surface between approximately 78 degrees north and south latitude. As the satellite revisits river systems over time, it builds a dynamic record of changing water levels and surface extent. This temporal coverage allows researchers to observe seasonal flooding, drought development, sediment transport patterns, and long-term hydrological trends.
One of the mission’s key scientific advances is the ability to measure river slope continuously along large distances. River flow is fundamentally governed by differences in gravitational potential energy, which are reflected in water surface gradients. By mapping these gradients accurately, scientists can estimate discharge rates even in regions where no ground gauges exist. This represents a major improvement in hydrological modeling capability.
The observations are particularly valuable in remote and under-monitored regions. Large river systems such as the Amazon, Congo, and Mekong include areas where conventional measurements are sparse or difficult to maintain. SWOT provides a uniform observational framework that allows direct comparison between river systems worldwide.
The mission also contributes to climate science. Hydrological cycles are strongly influenced by climate variability and long-term warming trends. Changes in precipitation patterns, glacier melt, and evapotranspiration affect river behavior at continental scales. Continuous global measurements improve the ability of climate models to represent freshwater transport and storage, reducing uncertainty in future projections.
Flood forecasting is another major application. River floods develop through complex interactions between rainfall, upstream flow, terrain, and infrastructure. High-resolution measurements of water surface elevation and floodplain extent improve the initialization and validation of hydrodynamic models. This can enhance prediction accuracy and support emergency management efforts.
The engineering challenge extends beyond the spacecraft itself into data processing and distribution. SWOT generates large volumes of radar data that must be converted into scientifically usable products. Signal processing algorithms remove atmospheric effects, radar noise, and surface scattering artifacts. Water detection algorithms distinguish rivers and lakes from surrounding terrain. Calibration systems ensure long-term consistency across observations.
The resulting datasets include measurements of river width, surface elevation, slope, and spatial extent. Combining these measurements with hydrological models allows scientists to estimate discharge and water storage changes over time. The data are distributed to researchers worldwide, enabling applications across hydrology, ecology, climate science, and resource management.
The mission also highlights the increasing role of international collaboration in Earth observation. Large-scale hydrological monitoring requires expertise in radar engineering, orbital systems, geophysics, and computational science. Contributions from multiple space agencies allowed the mission to combine technical capabilities and scientific objectives into a unified observational system.
From a broader perspective, SWOT represents a transition in how freshwater systems are studied. Historically, river science relied heavily on point measurements and regional studies. SWOT introduces a planetary-scale observational framework where rivers can be monitored consistently across continents and over time. This changes not only the quantity of available data, but also the types of scientific questions that can be addressed.
Researchers can now analyze interactions between river systems and climate processes globally rather than locally. They can observe how drought propagates through watersheds, how floodplains evolve seasonally, and how human activities alter natural flow patterns. The continuity and spatial coverage of the measurements provide a level of context that was previously unavailable.
The Mississippi River, the Amazon, and thousands of smaller systems can now be studied within the same measurement framework. This consistency improves comparative analysis and strengthens the ability to identify large-scale hydrological trends.
In practical terms, SWOT provides a new observational capability for managing one of Earth’s most important resources: freshwater. Scientifically, it represents one of the most advanced applications of radar interferometry in Earth observation. By transforming rivers into continuously measured global systems, the mission expands both the scale and precision of hydrological science.
Video credit: NASA Goddard
Featured blog posts
Posted on May 24, 2026
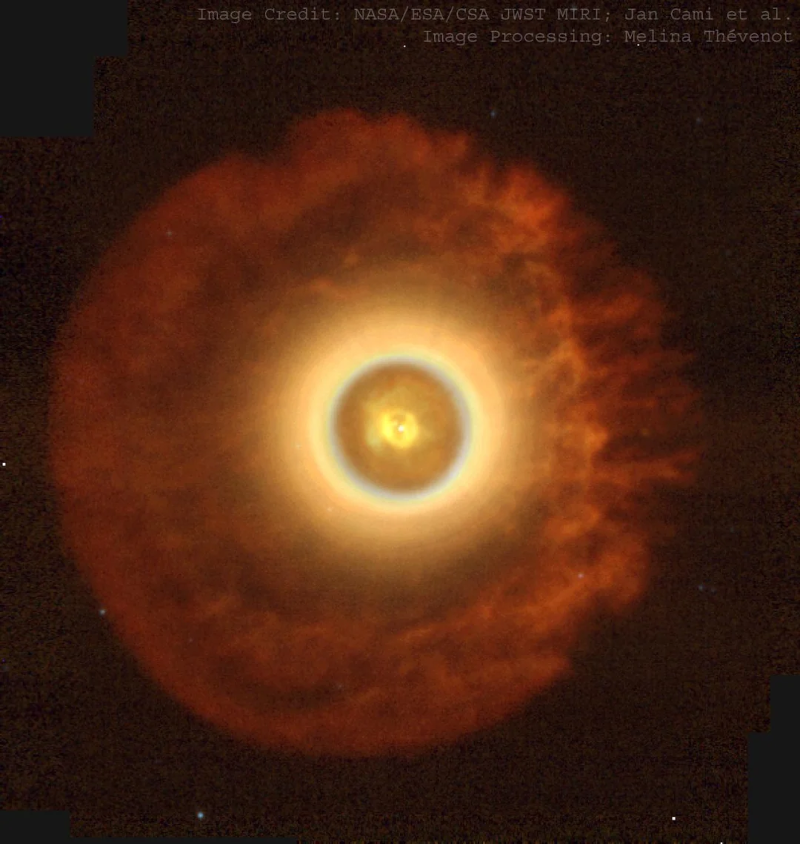 New observations from the James Webb Space Telescope are providing the clearest and most detailed view yet of the environment where these carbon structures form and evolve.
New observations from the James Webb Space Telescope are providing the clearest and most detailed view yet of the environment where these carbon structures form and evolve.  Engineers and scientists are assembling a spacecraft designed for a specific and increasingly important purpose: finding potentially hazardous objects before they find Earth.
Engineers and scientists are assembling a spacecraft designed for a specific and increasingly important purpose: finding potentially hazardous objects before they find Earth. Posted on May 4, 2026
 An international team of researchers announced that NASA's Curiosity rover had identified more than 20 distinct organic molecules preserved in ancient Martian rocks.
An international team of researchers announced that NASA's Curiosity rover had identified more than 20 distinct organic molecules preserved in ancient Martian rocks.  To truly shorten the distances between planets, something more powerful is required—something that does not merely burn fuel, but transforms matter itself into energy.
To truly shorten the distances between planets, something more powerful is required—something that does not merely burn fuel, but transforms matter itself into energy.  There are moments in engineering when progress is obvious. And then there are moments when progress looks like subtraction.
There are moments in engineering when progress is obvious. And then there are moments when progress looks like subtraction.  For as long as humans have pushed aircraft beyond the speed of sound, there has been a cost to that achievement—an invisible but unmistakable shockwave that ripples across the sky and crashes into the ground as a sonic boom.
For as long as humans have pushed aircraft beyond the speed of sound, there has been a cost to that achievement—an invisible but unmistakable shockwave that ripples across the sky and crashes into the ground as a sonic boom.  There are moments in the history of technology when an idea appears so simple in form and so vast in implication that it changes how we think about the future.
There are moments in the history of technology when an idea appears so simple in form and so vast in implication that it changes how we think about the future.  The American Institute of Aeronautics and Astronautics has released a groundbreaking report identifying ten technologies that will fundamentally reshape aerospace.
The American Institute of Aeronautics and Astronautics has released a groundbreaking report identifying ten technologies that will fundamentally reshape aerospace.  Every propulsion revolution has been delayed not by imagination, but by power.
Every propulsion revolution has been delayed not by imagination, but by power.  The LASER taught us that energy does not need to explode outward to be useful. It can be channeled. It can be persuaded to exit matter in an orderly way.
The LASER taught us that energy does not need to explode outward to be useful. It can be channeled. It can be persuaded to exit matter in an orderly way. Latest blog posts
Posted on May 24, 2026
New observations from the James Webb Space Telescope are providing the clearest and most detailed view yet of the environment where these carbon structures form and evolve.  The water aboard 3I/ATLAS, the third confirmed interstellar comet to visit our solar system, carries a chemical fingerprint radically different from anything in our own planetary neighborhood.
The water aboard 3I/ATLAS, the third confirmed interstellar comet to visit our solar system, carries a chemical fingerprint radically different from anything in our own planetary neighborhood.  The Surface Water and Ocean Topography mission, commonly known as SWOT, provides the first capability to continuously measure rivers and surface water systems globally from space at high spatial resolution.
The Surface Water and Ocean Topography mission, commonly known as SWOT, provides the first capability to continuously measure rivers and surface water systems globally from space at high spatial resolution.  NASA's High Performance Spaceflight Computing project is developing a radiation-hardened system-on-a-chip that promises to deliver up to 500 times the computational capacity of current spaceflight processors.
NASA's High Performance Spaceflight Computing project is developing a radiation-hardened system-on-a-chip that promises to deliver up to 500 times the computational capacity of current spaceflight processors. Posted on May 21, 2026
 On May 13, 2026, NASA published new details about the Artemis 3 mission and the changes were striking enough to warrant attention not for what they added, but for what they removed.
On May 13, 2026, NASA published new details about the Artemis 3 mission and the changes were striking enough to warrant attention not for what they added, but for what they removed. Posted on May 20, 2026
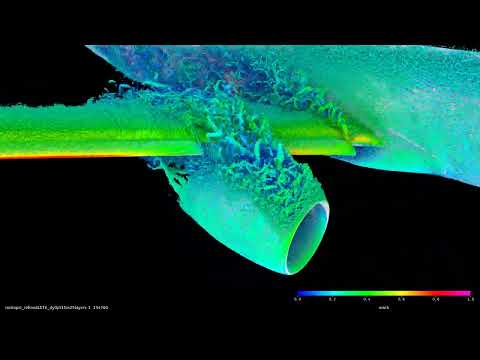 Takeoff and landing places complex aerodynamic demands on the aircraft, particularly around the wing surfaces, flaps, and slats collectively known as high-lift systems. Understanding how air behaves around these structures is one of the most challenging problems in aerospace engineering.
Takeoff and landing places complex aerodynamic demands on the aircraft, particularly around the wing surfaces, flaps, and slats collectively known as high-lift systems. Understanding how air behaves around these structures is one of the most challenging problems in aerospace engineering.  On May 4, 2026, a team led by Ko Arimatsu at the National Astronomical Observatory of Japan published a paper in Nature Astronomy reporting the detection of an atmosphere on the trans-Neptunian object (612533) 2002 XV93.
On May 4, 2026, a team led by Ko Arimatsu at the National Astronomical Observatory of Japan published a paper in Nature Astronomy reporting the detection of an atmosphere on the trans-Neptunian object (612533) 2002 XV93. Posted on May 19, 2026
 In the early hours of March 17, 2026, engineers at the European Space Agency watched as a spacecraft roughly 1.6 billion kilometers away executed the largest trajectory correction of its mission.
In the early hours of March 17, 2026, engineers at the European Space Agency watched as a spacecraft roughly 1.6 billion kilometers away executed the largest trajectory correction of its mission. Posted on May 18, 2026
 Roughly 1,000 light-years from Earth, astronomers have identified an enormous protoplanetary disk surrounding a young star system, a structure so large that it extends nearly 400 billion miles across.
Roughly 1,000 light-years from Earth, astronomers have identified an enormous protoplanetary disk surrounding a young star system, a structure so large that it extends nearly 400 billion miles across.  SpaceX has set no earlier than May 19, 2026, for the first flight of Starship in its Version 3 configuration.
SpaceX has set no earlier than May 19, 2026, for the first flight of Starship in its Version 3 configuration. Posted on May 16, 2026
 The European Space Agency announced in February 2026 that contracts for the Ramses spacecraft had been awarded following a successful final design review.
The European Space Agency announced in February 2026 that contracts for the Ramses spacecraft had been awarded following a successful final design review.  In the coming days, a spacecraft launched from Cape Canaveral in October 2023 will pass close enough to Mars to feel the planet's gravity bend its trajectory.
In the coming days, a spacecraft launched from Cape Canaveral in October 2023 will pass close enough to Mars to feel the planet's gravity bend its trajectory.  Subscribe to blog posts using RSS
Subscribe to blog posts using RSS










